
Task 1: Punctuation prediction from conversational language
Restore punctuation marks from the output of an ASR system.
Authors
Piotr Pęzik, Adam Wawrzyński, Michał Adamczyk, Sylwia Karasińska, Wojciech Janowski, Agnieszka Mikołajczyk, Filip Żarnecki, Patryk Neubauer and Anna Cichosz
Video introduction
Motivation
Speech transcripts generated by Automatic Speech Recognition (ASR) systems typically do not contain any punctuation or capitalization. In longer stretches of automatically recognized speech, lack of punctuation affects the general clarity of the output text [1]. The primary purpose of punctuation restoration (PR), punctuation prediction (PP), and capitalization restoration (CR) as a distinct natural language processing (NLP) task is to improve the legibility of ASR-generated text and possibly other types of texts without punctuation. For the purposes of this task, we define PR as restoration of originally available punctuation from read speech transcripts (which was the goal of a separate task in the PolEval 2021 competition) [2] and PP as prediction of possible punctuation in transcripts of spoken/ conversational language. Aside from their intrinsic value, PR, PP, and CR may improve the performance of other NLP aspects such as Named Entity Recognition (NER), part-of-speech (POS), and semantic parsing or spoken dialog segmentation [3, 4].
One of the challenges of developing PP models for conversational language is the availability of consistently annotated datasets. The very nature of naturally-occurring spoken language makes it difficult to identify exact phrase and sentence boundaries [5,6], which means that dedicated guidelines are required to train and evaluate punctuation models.
The goal of the present task is to provide a solution for predicting punctuation in the test set collated for this task. The test set consists of time-aligned ASR dialogue transcriptions from three sources:
- CBIZ, a subset of DiaBiz, a corpus of phone-based customer support line dialogs (https://clarin-pl.eu/dspace/handle/11321/887)
- VC, a subset of transcribed video-communicator recordings
- SPOKES, a subset of the Spokes corpus [7]
Table 1 below summarizes the size of the three subsets in terms of dialogs, words and duration of recordings.
| Subset | Corpus | Files | Words | Audio [s] | Speakers | License |
|---|---|---|---|---|---|---|
| CBIZ | DiaBiz | 69 | 36 250 | 16 916 | 14 | CC-BY-SA-NC-ND |
| VC | Video conversations | 8 | 44 656 | 17 123 | 20 | CC-BY-NC |
| Spokes | Casual conversations | 13 | 42 730 | 20 583 | 19 | CC-BY-NC |
Table 1. Overall statistics of the corpus.
The full dataset has been split into three subsets as summarized in Table 2 below.
| Set | Files | Words | Audio [s] | License |
|---|---|---|---|---|
| Train | 69 | 98 095 | 44 030 | CC-BY-SA-NC-ND |
| Dev | 11 | 12 563 | 4 718 | CC-BY-NC |
| Test | 10 | 12 978 | 5 874 | CC-BY-NC |
Table 2. Training / development / test set statistics.
The punctuation annotation guidelines were developed in the CLARIN-BIZ project by Karasińska et al. [10].
Participants are encouraged to use both text-based and speech-derived features to identify punctuation symbols (e.g. multimodal framework [8]) or to predict casing along with punctuation [9]. We allow using the punctuation dataset available from: PolEval 2021: Task 1. Punctuation restoration from read text [2].
Task description
The workflow of this task is illustrated in Fig 1 below. Given raw ASR output, the task is to predict punctuation in annotated ASR transcripts of conversational speech.
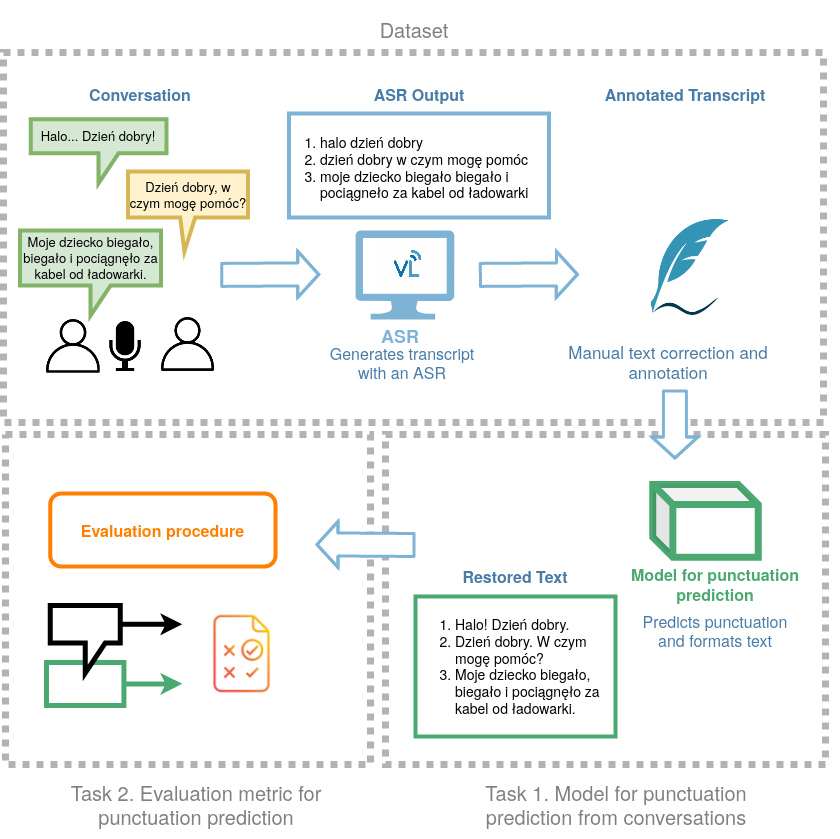
Fig. 1 Overview of the punctuation prediction task.
The punctuation marks evaluated as part of the task are listed in Table 3 below. Blanks are marked as spaces. The distribution of explicit punctuation symbols in the training and development portion of the dataset provided is shown in Tables 3-6.
| Symbol | Mean per dialog | Median | Max | Sum | |
|---|---|---|---|---|---|
| fullstop | . | 111.15 | 59 | 1 157 | 8 892 |
| comma | , | 161.51 | 69 | 1 738 | 12 921 |
| question_mark | ? | 24.36 | 11 | 229 | 1 949 |
| exclamation_mark | ! | 3.46 | 4 | 45 | 277 |
| hyphen | - | 0.64 | 25 | 50 | 51 |
| ellipsis | … | 63.28 | 11 | 1 833 | 5 062 |
| words | 1 383.23 | 569 | 16 528 | 110 658 |
Table 3. Punctuation for raw text (all subcorpora)
| Symbol | Mean per dialog | Median | Max | Sum | |
|---|---|---|---|---|---|
| fullstop | . | 58.06 | 54 | 213 | 3 600 |
| comma | , | 70.61 | 59 | 388 | 4 378 |
| question_mark | ? | 11.26 | 10 | 35 | 698 |
| exclamation_mark | ! | 0.34 | 1 | 5 | 21 |
| hyphen | - | 0.02 | 1 | 1 | 1 |
| ellipsis | … | 12.29 | 9 | 54 | 762 |
| words | 528.74 | 483 | 2 180 | 32 782 |
Table 4. Punctuation for raw text (CBIZ)
| Symbol | Mean per dialog | Median | Max | Sum | |
|---|---|---|---|---|---|
| fullstop | . | 411.86 | 384 | 1 157 | 2 883 |
| comma | , | 737.86 | 577 | 1 738 | 5 165 |
| question_mark | ? | 85.29 | 41 | 229 | 597 |
| exclamation_mark | ! | 10.43 | 5 | 43 | 73 |
| hyphen | - | / | / | / | / |
| ellipsis | … | 514.00 | 365 | 1 833 | 3 598 |
| words | 5 704.14 | 4 398 | 9 469 | 39 929 |
Table 5. Punctuation for raw text (VC)
| Symbol | Mean per dialog | Median | Max | Sum | |
|---|---|---|---|---|---|
| fullstop | . | 219.00 | 193 | 607 | 2 409 |
| comma | , | 307.09 | 313 | 614 | 3 378 |
| question_mark | ? | 59.45 | 39 | 150 | 654 |
| exclamation_mark | ! | 16.64 | 10 | 45 | 183 |
| hyphen | - | 4.55 | 50 | 50 | 50 |
| ellipsis | … | 63.82 | 45 | 186 | 702 |
| words | 3 449.73 | 1 966 | 16 528 | 37 947 |
Table 6. Punctuation for raw text (Spokes)
Data format
We provide two types of data: text and audio data. Text data is provided in the TSV format. For Audio data we provide audio files as WAV files and transcripts with force-aligned timestamps.
WAVE files are provided as a separate download:
- train and dev audio files: http://poleval.pl/task1/train-dev-audio.zip
- test audio files: http://poleval.pl/task1/test-audio.zip
Text data
The datasets are encoded in the TSV format.
Field descriptions:
- column 1: name of the audio file
- column 2: unique segment id
- column 3: segment text, where each word is separated by a single space
The segment text (column 3) format is:
- single word text:word start timestamp in ms-word end timestamp in ms
Evaluation procedure
The baseline results will be provided in the final evaluation.
Submission format
Results are to be submitted as plain text file, where each line corresponds to a single segment. The text should include the predicted punctuation marks.
Metrics
Final results are evaluated in terms of precision, recall, and F1 scores for predicting each punctuation mark separately. Submissions are compared with respect to the weighted average of F1 scores for each punctuation sign. The method of evaluation is similar to the one used in the previous PolEval competition, PolEval 2021: Task 1. Punctuation restoration from read text [2]
Per-document score:
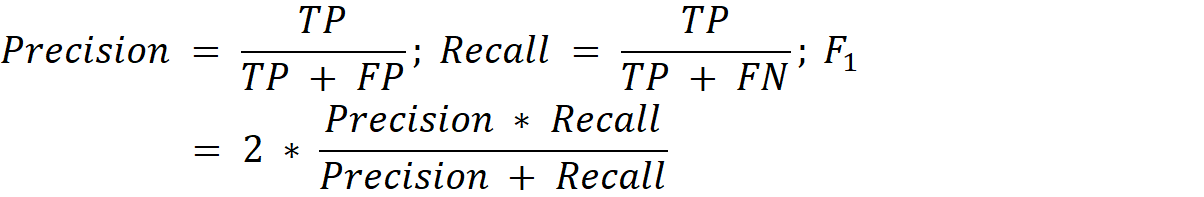
Global score per punctuation sign p:

Final scoring metric calculated as weighted average of global scores per
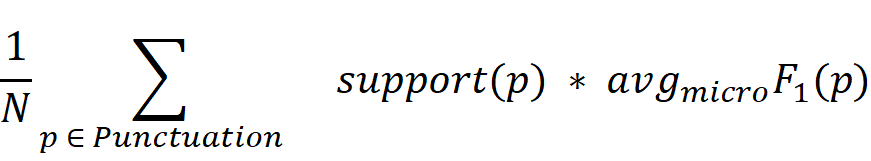
We would like to invite participants to a discussion about evaluation metrics, taking into account such factors as
- ASR and Forced-Alignment errors,
- inconsistencies among annotators,
- the impact of only slight displacement of punctuation,
- assigning different weights to different types of errors.
Metadata
Tags: poleval-2022, asr
References
- Yi, J., Tao, J., Bai, Y., Tian, Z., & Fan, C. (2020). Adversarial transfer learning for punctuation restoration. arXiv preprint arXiv:2004.00248.
- Mikołajczyk, A., Wawrzynski, A., Pezik, P., Adamczyk, M., Kaczmarek, A., & Janowski, W. PolEval 2021 Task 1: Punctuation Restoration from Read Text. Proceedings ofthePolEval2021Workshop, 21.
- Nguyen, Thai Binh, et al. “Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models.” Proc. Interspeech 2020 (2020): 4263-4267.
- Hlubík, Pavel, et al. “Inserting Punctuation to ASR Output in a Real-Time Production Environment.” International Conference on Text, Speech, and Dialogue. Springer, Cham, 2020.
- Sirts, Kairit, and Kairit Peekman. “Evaluating Sentence Segmentation and Word Tokenization Systems on Estonian Web Texts.” Human Language Technologies–The Baltic Perspective: Proceedings of the Ninth International Conference Baltic HLT 2020. Vol. 328. IOS Press, 2020.
- Wang, Xueyujie. “Analysis of Sentence Boundary of the Host’s Spoken Language Based on Semantic Orientation Pointwise Mutual Information Algorithm.” 2020 12th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA). IEEE, 2020.
- Pezik, P. (2014, October). Spokes-a search and exploration service for conversational corpus data. In Selected papers from the CLARIN 2014 Conference (pp. 99-109).
- Sunkara, Monica, et al. “Multimodal Semi-supervised Learning Framework for Punctuation Prediction in Conversational Speech.” arXiv preprint arXiv:2008.00702 (2020).
- Pappagari, R., Żelasko, P., Mikołajczyk, A., Pęzik, P., & Dehak, N. (2021). Joint prediction of truecasing and punctuation for conversational speech in low-resource scenarios. arXiv preprint arXiv:2109.06103.
- Karasińska S., Cichosz, A. Adamczyk M., Pęzik P. Evaluating punctuation prediction in conversational language. Forthcoming.